Comment l’INA s’est emparé de l’IA pour décrypter ses archives
Proposer un « regard inédit » sur des décennies d’archives audiovisuelles : telle est l’ambition de data.ina.fr, une plateforme lancée par l’Institut national de l’audiovisuel (INA). Déjà reconnu pour son rôle de média patrimonial, qui éclaire l’actualité grâce à ses archives, l’INA a adopté une démarche novatrice pour ce projet : s’appuyer sur l’intelligence artificielle pour analyser son immense volume d’archives. Avec l’objectif, derrière, d’en dégager des grandes tendances médiatiques.
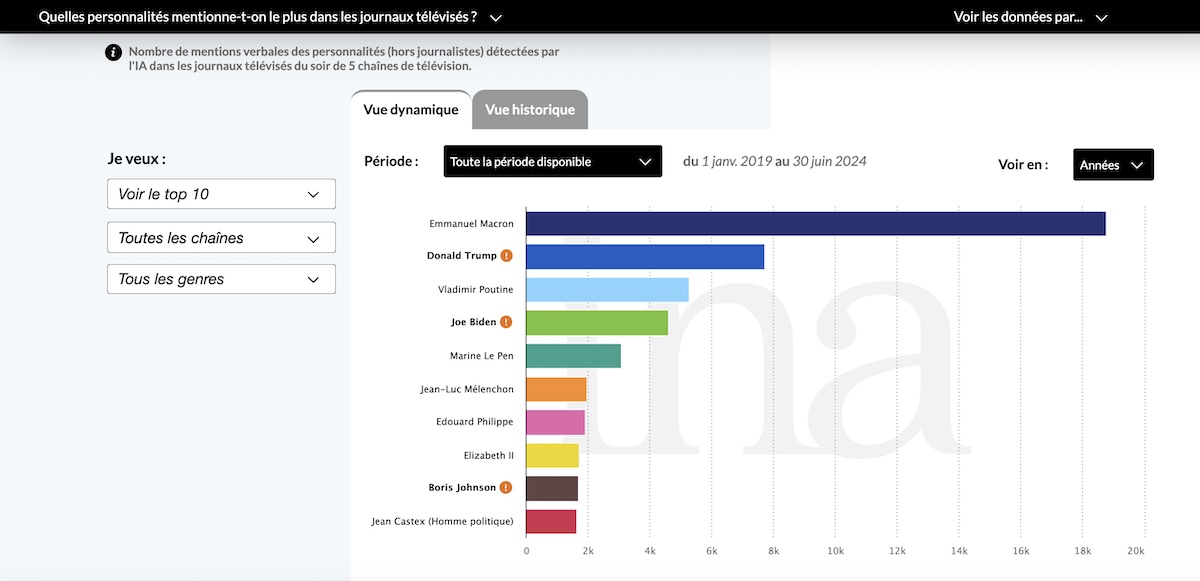
Pour réaliser la première version du site, déployée en octobre 2024, l’INA a ainsi traité et analysé plus de 700 000 heures de contenus audiovisuels, à l’aide de trois outils alimentés par l’intelligence artificielle, dont une solution conçue par son équipe de recherche. Un travail dantesque, qui a ensuite été soumis à un processus de vérification assuré par des humains. Il lui permet de répondre à plusieurs questions grâce à la datavisualisation, telles que l’évolution de la couverture médiatique d’un terme (par exemple, « shrinkflation » ou « ChatGPT ») ou encore la fréquence à laquelle certaines personnalités sont citées sur les plateaux.
Pour mieux comprendre les enjeux et les objectifs d’une plateforme assez inédite dans le paysage médiatique, et qui s’enrichira tous les six mois d’une nouvelle profondeur historique, BDM s’est entretenu avec Camille Pettineo, responsable éditoriale de data.ina.fr et Xavier Lemarchand, directeur de mission coordination et intégration de l’IA à l’INA.

Camille Pettineo, responsable éditoriale de data.ina.fr
Titulaire d’un master en journalisme obtenu à l’École de journalisme et de communication d’Aix-Marseille, Camille Pettineo est data-journaliste et s’est spécialisée dans les outils IA pour les mettre au service du journalisme. Elle a intégré l’INA en mai 2023 en tant qu’adjointe au rédacteur en chef et se consacre à l’exploitation éditoriale de la data, notamment via data.ina.fr et la Revue des Médias

Xavier Lemarchand, directeur de mission coordination et intégration IA à l’INA
Titulaire d’un doctorat en sciences de l’information et de la communication obtenu à l’Université de technologie de Compiègne, Xavier Lemarchand a rejoint l’INA en 1995 en tant que chargé de mission. Actuellement directeur de mission, il est chargé du pilotage transverse de l’intégration de l’intelligence artificielle et de ses enjeux stratégiques au sein de l’INA.
Depuis quand l’INA s’intéresse-t-il aux possibilités offertes par l’intelligence artificielle ?
XAVIER LEMARCHAND – Depuis sa création, l’INA dispose d’un département de recherche, qui était initialement axé sur les sciences humaines et sociales dans le domaine des médias. Mais une bascule s’est opérée dans les années 2000 avec l’émergence de problématiques liées à l’analyse automatique des contenus, en parallèle du processus de numérisation des archives. L’INA a alors recruté des chercheurs aux profils plus techniques, qui ont commencé à travailler à la conception d’algorithmes et qui commençaient déjà à utiliser le machine learning.
Depuis, l’équipe de recherche a conçu plusieurs outils, comme Snoop, axé sur la recherche d’images et la classification d’objets, qui permet de retrouver des images très proches ou incluant des objets comparables dans les archives audiovisuelles. Nous avons également développé INASpeechSegmenter, que l’on utilise sur la plateforme data.ina.fr. Et qui permet de distinguer, par exemple, les locuteurs perçus comme féminins ou masculins.
Ces outils ont été développés en interne, mais nous n’avons pas les ressources pour développer toutes les solutions dont nous avons besoin. L’INA a donc une logique opportuniste : quand un outil « sur étagère » répond à un besoin, on le teste, puis on essaie de l’intégrer, dans la mesure du possible, à nos systèmes d’information, tout en veillant à rester le plus autonome possible.
Avec data.ina.fr, nous explorons encore une autre voie. Ce ne sont plus uniquement les archives qui nous intéressent, ce sont aussi les métadonnées.
Pourquoi avoir choisi d’utiliser l’IA pour valoriser les archives de l’INA, au travers de cette nouvelle plateforme ?
XAVIER LEMARCHAND – L’intelligence artificielle répond à trois enjeux de l’INA. Le premier, et sans doute le plus important, concerne la découvrabilité : ces « IA descriptives » permettent de décrire le plus finement et exhaustivement possible l’ensemble de nos contenus audiovisuels, et donc de faciliter leur exploration. Elles sont capables, dans le même temps, de traiter de grandes quantités de données qui ont un intérêt pour l’analyse et la détection de grandes tendances sur le long terme. Enfin, bien que cela soit un peu éloigné du projet data.ina.fr, l’IA contribue à l’amélioration de la qualité audiovisuelle. Car nous avons des problématiques liées à nos supports : presque deux-tiers des archives audiovisuelles de l’INA sont en basse résolution. Et notre mission est aussi de pouvoir valoriser ces contenus, en explorant des solutions capables de corriger leurs défauts ou de les adapter aux standards techniques actuels.
CAMILLE PETTINEO – Cela contribue aussi à faire de l’INA un média distinctif. Historiquement, l’INA joue un rôle de média patrimonial, qui éclaire l’actualité au travers des archives. Ces dernières années, notre périmètre s’est élargi, avec entre autres le lancement de INA Hip Hop sur YouTube, TikTok et Snapchat, ainsi que du service de streaming madelen, en 2020. Avec data.ina.fr, nous explorons encore une autre voie. Ce ne sont plus uniquement les archives qui nous intéressent, ce sont aussi les métadonnées. L’enjeu est de donner du sens à cette vaste quantité de données, ce qui correspond à la définition même du datajournalisme. Une forme de journalisme que l’on pratique déjà, au travers d’enquêtes publiées sur la Revue des Médias, comme celle qui traite de la médiatisation des violences sexistes et sexuelles. Mais avec cette plateforme, ces techniques de datajournalisme deviennent accessibles. Le grand public peut s’en saisir, sans disposer de compétences techniques ou de formations préalables – ce qui est un peu révolutionnaire – pour explorer les archives sous un autre angle, avec des grandes tendances statistiques.

Et nous ne nous sommes pas arrêtés là. Sur notre plateforme, nous adoptons une démarche à la fois vulgarisatrice et pédagogique, car l’utilisation de l’IA comporte des risques de biais et d’hallucinations. Il fallait accompagner cette révolution de l’information. Autour de chaque graphique, nous avons intégré des explications sur la manière de lire les données, par exemple, ou des infographies dans la méthodologie, qui détaillent comment, à partir d’une vidéo, on obtient les résultats qu’on présente sur la plateforme.
Vous avez utilisé deux outils développés par des startups pour traiter et analyser l’immense quantité de données : Whisper et TextRazor. Pourquoi avoir choisi ces technologies ?
XAVIER LEMARCHAND – Le choix des outils est lié à leur fiabilité, d’une part, et à notre capacité à les intégrer dans nos pipelines industriels de traitement, d’autre part. Concernant Whisper, nous avons comparé plusieurs outils de transcription et c’est indéniablement l’un des plus plus fiables aujourd’hui. En plus, c’est un outil open source, ce qui nous permet de l’intégrer plus facilement à nos systèmes d’information et ainsi d’être autonomes. Ça nous évite d’envoyer des vidéos en dehors de notre infrastructure, et ainsi conserver une forme de souveraineté sur nos archives et nos données.
700 000 heures de contenus ont été analysées pour réaliser la première version de ce site. Si l’on veut mettre ça en perspective : une personne qui atteint l’âge de 100 ans a vécu 876 000 heures.
Comment la pertinence du travail réalisé par ces outils est-elle contrôlée ?
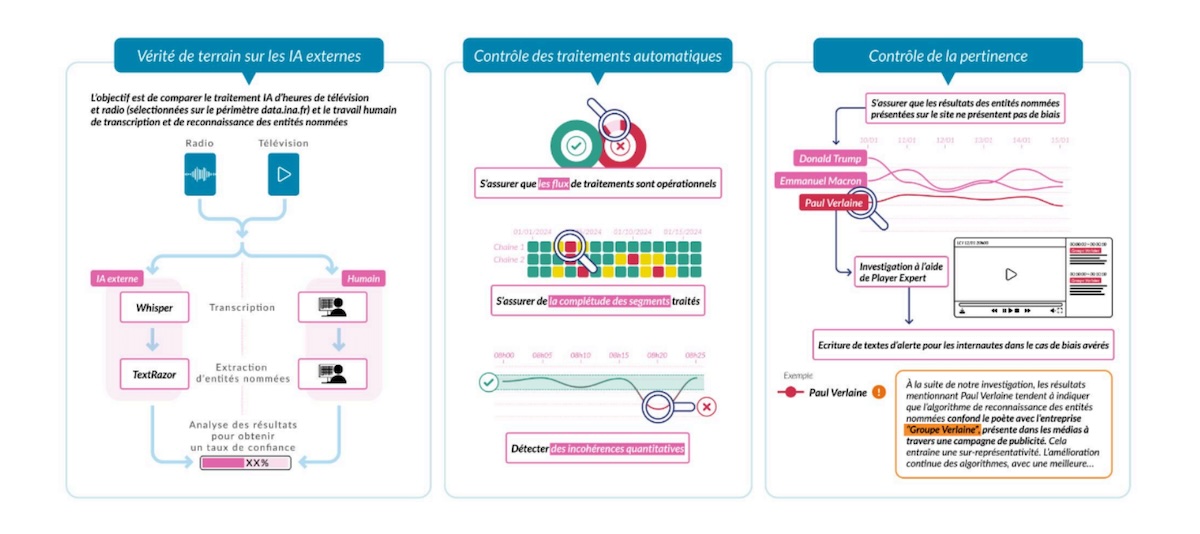
XAVIER LEMARCHAND – Pour garantir la fiabilité des données proposées par ces outils, nous avons mis en place trois étapes de contrôles.
La première, c’est la « vérité terrain ». L’idée est de constituer un corpus d’archives représentatif de l’ensemble du périmètre, sur lequel nous demandons à des humains d’effectuer un travail de transcription, de repérage d’entités nommées, etc. Puis, nous comparons les données avec celles générées par l’IA, afin d’obtenir un taux de confiance. Par exemple, sur le processus de repérage d’entités nommées, nous avons un taux de confiance de 83 %. C’est bien, mais pas parfait : en creusant, nous allons détecter des erreurs récurrentes.
Le second contrôle concerne l’exhaustivité du traitement automatique. Il permet de s’assurer qu’il n’y a pas de « trou dans la raquette » et que toutes les plages de notre périmètre sont traitées.
Enfin, la troisième étape est un « contrôle de pertinence ». Il consiste à vérifier, sur les tops 20 mensuels de toutes les chaînes, que les entités nommées détectées par l’IA correspondent réellement aux personnes mentionnées. Ce processus permet de repérer, par exemple, que l’IA confond parfois la Milice Wagner avec Richard Wagner.
CAMILLE PETTINEO – L’INA a également fait un choix fort, et assez unique en son genre, en décidant de ne pas corriger les biais et les hallucinations des IA, mais simplement de les signaler. Pourquoi ? Parce qu’à l’échelle des volumes traités, ça n’aurait pas de sens. 700 000 heures de contenus ont été analysées pour réaliser la première version de ce site. Si l’on veut mettre ça en perspective : une personne qui atteint l’âge de 100 ans a vécu 876 000 heures. La vérification manuelle est donc impossible, pour un tel volume de données.
Et par ailleurs, effectuer des corrections, ce serait prendre le risque d’ajouter des biais humains à des biais techniques, algorithmiques. Ce qui peut sembler être une erreur à un moment donné pourrait être perçu différemment plus tard. Ça nous forcerait à revenir en arrière en permanence.
Quels critères ont été utilisés pour définir le périmètre d’analyse ?
XAVIER LEMARCHAND – D’abord, nous avons voulu nous concentrer sur les contenus d’actualité, car nous avons estimé qu’il s’agissait du domaine sur lequel l’attente était la plus forte. C’était un critère thématique, d’où le choix de traiter des archives provenant de JT, des chaînes généralistes, de chaînes d’information et de matinales de radio, en définissant parallèlement des plages horaires. Sur le plan temporel, on voulait avoir d’emblée plusieurs années de données exploitables, car nous estimons que l’intérêt de ces IA réside dans leur capacité à mettre en évidence des tendances sur des périodes étendues. Pour lancer la première version du site, nous avons attendu d’avoir cinq années de données exploitables. Et nous étendons dès janvier 2025 ce périmètre à dix années (2015-2024).
Concernant le périmètre fonctionnel, le critère principal, c’était la maturité des outils. C’est-à-dire que nous avons considéré, après plusieurs tests d’évaluation, que les capacités de transcription, de repérage d’entités nommés et de détection des locuteurs femmes-hommes étaient suffisamment matures pour produire des données pertinentes.
CAMILLE PETTINEO – Sur le plan éditorial, nous ne nous interdisons pas d’ajouter des questions supplémentaires, à l’avenir. Nous avons déjà plus d’une dizaine de questions et près de trente graphiques. Ce qui était important pour nous, sur cette première version, c’était d’aller le plus loin possible dans la personnalisation de l’expérience. L’utilisateur a la possibilité de choisir sa période, de visualiser des top 10, des top 20, de faire ses propres recherches… En matière de visualisation, une granularité par année, par mois ou par jour est également proposée. Il fallait faire des choix, et nous avons misé sur la personnalisation de l’expérience.
Peut-on imaginer la création d’un dispositif similaire pour exploiter les données collectées par le dépôt légal du web ?
XAVIER LEMARCHAND – L’idée nous a traversé l’esprit, mais nous butons sur la question de l’homogénéité du corpus. Lorsqu’on regarde la télévision ou qu’on écoute la radio, les grilles de programmes, les créneaux horaires et les thématiques sont bien définies. Ça facilite les comparaisons, car le périmètre est compréhensible par tous. Sur le web, tout est plus complexe. La nature des contenus, les acteurs, les producteurs, les périmètres de diffusion… Tout cela est très hétérogène. Le défi n’est pas seulement de traiter techniquement les archives audiovisuelles du web, mais de pouvoir interpréter les résultats. Comment peut-on en tirer des enseignements, alors que tout n’est pas forcément comparable ou cohérent ? Ce n’est pas complètement mûr, pour le dire autrement.
www.blogdumoderateur.com
Khamallah Abdel khalik









0 Comments